
Memahami Teknik Normalisasi Lanjut Perancangan Basis Data
Memahami Teknik Normalisasi Lanjut Perancangan Basis Data - Normalisasi adalah langkah-langkah sistematis untuk menjamin bahwa struktur database memungkinkan untuk general purpose query dan bebas dari insertion, update dan deletion anomalies yang dapat menyebabkan hilangnya integritas data. Melalui artikel ini diharapkan dapat mengetahui dan memahami mengenai teknik normalisasi.
Perancangan basis data diperlukan, agar kita bisa memiliki basis data yang kompak dan efisien dalam penggunaan ruang penyimpanan, cepat dalam pengaksesan dan mudah dalam pemanipulasian (tambah, ubah, hapus) data. Dalam merancang basis data, kita dapat melakukannya dengan :
1. Definisi Normalisasi
Normalisasi diartikan sebagai suatu teknik yang menstrukturkan/ mendekomposisi/ memecah data dalam cara–cara tertentu untuk mencegah timbulnya permasalahan pengolahan data dalam basis data. Permasalahan yang dimaksud adalah berkaitan dengan penyimpangan–penyimpangan (anomalies) yang terjadi akibat adanya kerangkapan data dalam relasi dan inefisiensi pengolahan.
Proses normalisasi akan menghasilkan relasi yang optimal, yaitu :
Dalam pendekatan normalisasi, perancangan basis data bertitik tolak dari situasi nyata. Ia telah memiliki item–item data yang siap ditempatkan dalam baris dan kolom pada tabel–tabel relasional. Demikian juga dengan sejumlah aturan tentang keterhubungan antara item–item data tersebut. Sementara pendekatan model data ER lebih tepat dilakukan jika yang diketahui baru prinsip sistem secara keseluruhan.
Cukup sering pendekatan ini dilakukan bersama–sama, berganti–ganti. Dari fakta yang telah kita miliki, kita lakukan normalisasi. Untuk kepentingan evaluasi dan dokumentasi, hasil normalisasi itu kita wujudkan dalam sebuah model data. Model data yang sudah jadi tersebut bisa saja dimodifikasi dengan pertimbangan tertentu. Hasil modifikasinya kemudian kita implementasikan dalam bentuk sejumlah struktur tabel dalam sebuah basis data. Struktur ini dapat kita uji kembali dengan menerapkan aturan–aturan normalisasi, hingga akhirnya kita peroleh sebuah struktur basis data yang benar–benar efektif dan efisien. Begitulah kedua pendekatan dapat saling memperkuat satu sama lain.
2. Tujuan Normalisasi
Pada dasarnya normalisasi dilakukan untuk memperbaiki desain tabel yang kurang baik sehingga penyimpanan data menjadi lebih efisien dan bebas anomali data. Untuk memperjelas pemahaman tentang proses normalisasi, perhatikan diagram berikut:
3. Atribut Tabel
Atribut yang sebenarnya identik dengan pemakaian istilah kolom data. Istilah atribut ini lebih umum digunakan dalam perancangan basis data, karena istilah itu lebih impresif dalam menunjukkan fungsinya sebagai pembentuk karakteristik (sifat–sifat) yang melekat pada sebuah table.
a. Atribut Sederhana (Simple Attribute) dan Atribut Komposit (Composite Attribute)
Atribut sederhana adalah atribut atonik yang tidak dapat dipilah lagi. Sementara atribut komposit merupakan atribut yang masih dapat diuraikan lagi menjadi sub–sub atribut yang masing–masing memiliki makna.
Contoh pada tabel mahasiswa, atribut nama_mhs merupakan atribut sederhana. Sedangkan alamat_mhs merupakan atribut komposit, karena dapat diuraikan menjadi beberapa sub atribut seperti alamat, nama_kota dan kode_pos yang masing–masing memiliki makna.

b. Atribut BernilaiTunggal (Single Valued Attribute) dan Atribut Bernilai Banyak (Multi Valued Atrtribute)
Atribut bernilai tunggal ditujukan pada atribut–atribut yang memiliki paling banyak satu nilai untuk setiap basis data. Pada data mahasiswa, semua atribut (nim, nama_mhs, alamat_mhs dan tgl_lahir) merupakan atribut bernilai tunggal, karena atribut–atribut tersebut hanya dapat berisi 1 (satu) nilai. Jika seorang mahasiswa yang memiliki 2 (dua) tempat tinggal, maka hanya salah satu saja yang boleh diisikan ke dalam atribut alamat_mhs.
Atribut bernilai banyak ditujukan pada atribut–atribut yang dapat kita isi dengan lebih dari 1 (satu) nilai, tetapi jenisnya sama. Kita dapat menambahkan atribut hobi, pada data mahasiswa tersebut. Seorang mahasiswa ada yang mempunyai 1 hobi saja, ada juga yang mempunyai hobi banyak dan bahkan ada mahasiswa yang tidak memiliki hobi. Atribut semacam ini tergolong atribut bernilai banyak.

c. Atribut Harus Bernilai (Mandatory Attribute) dan Nilai Null
Ada sejumlah atribut pada sebuah tabel yang kita tetapkan harus berisi data. Jadi nilainya tidak boleh kosong. Atribut semacam ini disebut Mandatory Attribute. Pada tabel mahasiswa, misalnya atribut nim dan nama_mhs dapat kita golongkan sebagai Mandatory Attribute, karena setiap mahasiswa yang datanya ingin disimpan ke tabel tersebut, paling tidak harus diketahui dengan pasti nim dan namanya. Sebaliknya pula atribut–atribut lain suatu tabel yang nilainya boleh dikosongkan (Non Mandatory Attribute). Nilai Null digunakan untuk menyatakan/ mengisi atribut–atribut demikian yang nilainya memang belum siap atau tidak ada.

d. Atribut Turunan
Atribut turunan adalah atribut yang nilai–nilainya diperbolehkan dari pengolahan atau dapat diturunkan dari atribut atau tabel lain yang berhubungan. Atribut demikian sebetulnya dapat ditiadakan dari sebuah tabel, karena nilai–nilainya bergantung pada nilai yang ada di atribut lainnya.
Penambahan atribut angkatan dan IP (Indeks Prestasi) pada tabel mahasiswa berikut merupakan contoh atribut turunan

4. Domain dan Tipe Data
Penetapan tipe data pada setiap atribut (kolom) untuk keperluan penentuan struktur setiap tabel. Penetapan tipe data ini akan berimplikasi pada adanya batas–batas nilai yang mungkin disimpan/diisikan kesetiap atribut tersebut. Jika kita menetapkan bahwa tipe data untuk sebuah atribut adalah integer, maka kita hanya mungkin untuk menyimpan data angka yang bulat diantara –32.768 hingga 32.768. Kita tidak mungkin untuk memasukkan data diluar batas nilai tersebut, data pecahan apalagi data berupa string/text.
Domain memiliki banyak kesamaan pengertian dengan fungsi tipe data tersebut. Akan tetapi, tipe data merujuk pada kemampuan penyimpanan data yang mungkin bagi suatu atribut secara fisik, tanpa melihat layak tidaknya data tersebut bila dilihat dari kenyataannya pemakaiannya. Sementara domain nilai lebih ditetapkan pada batas–batas nilai yang diperbolehkan bagi suatu atribut, dilihat dari kenyataanya yang ada.
Contoh : pada tabel kuliah, ditetapkan tipe data untuk atribut sks adalah integer. Dengan begitu secara fisik kita dapat menyimpan nilai –1, 0 atau 100 untuk atribut sks. Tetapi kita mengetahui dengan pasti, bahwa nilai–nilai tersebut tidak pantas (invalid) untuk menjadi data pada atribut sks. Lalu nilai–nilai yang boleh (valid) untuk atribut sks adalah 1, 2, 3, 4 dan 6, maka dapat dikatakan, domain nilai untuk atribut sks adalah 1, 2, 3, 4 dan 6.
Intinya, normalisasi dilakukan terhadap desain tabel yang sudah ada dengan tujuan untuk meminimalkan redundansi (pengulangan) data dan menjamin integritas data dengan cara menghidari 3 Anomali Data: Update, Insertion dan Deletion Anomaly.
a. Update Anomaly
Tabel di atas adalah contoh tabel yang memiliki desain yang kurang baik. Perhatikan bahwa jika kita ingin meng-update jumlah sks mata kuliah English dari 2 menjadi 3 sks, maka kita harus mengupdate lebih dari 1 record, yaitu baris 2 dan 4.
Jika hanya salah satu baris saja yang di-update, maka data menjadi tidak konsisten (ada mata kuliah English dengan 2 sks dan ada mata kuliah English dengan 3 sks) . Kondisi seperti inilah yang disebut dengan update anomaly.
b. Insertion Anomaly
Modul Makalah - Pada tabel yang sama seperti contoh di atas, terjadi pula insertion anomaly. Misalkan terdapat mahasiswa baru dengan nim 1-02 bernama ‘Zubaedah’ dengan kode jurusan ‘TE’ dan nama jurusan ‘Elektro’.
Data mahasiswa tersebut tidak dapat dimasukkan ke dalam tabel sebab dia belum mengambil kuliah apapun (misalnya karena belum melakukan registrasi). Kondisi inilah yang disebut dengan insertion anomaly.
c. Deletion Anomaly
Pada contoh tabel di atas terjadi deletion anomaly. Perhatikan bahwa jika kita menghapus data mahasiswa bernama ‘Maemunah’ maka kita harus menghapus data pada baris ke 5, hal ini akan mengakibatkan kita juga kehilangan data mata kuliah ‘Database’. Kondisi inilah yang disebut dengan deletion anomaly.
Selain 3 anomali di atas, ada beberapa konsep yang mendasari normalisasi. Adapun konsep-konsep penting yang mendasari normalisasi adalah konsep mengenai super key, candidate key, primary key, functional dependency dan tentu saja bentuk-bentuk normal yang menjadi acuan kita dalam melakukan normalisasi terhadap desain sebuah tabel. Pemahaman terhadap konsep-konsep ini sangat penting dan akan dibahas di beberapa sub bab berikutnya.
2. The Three Keys
Konsep tentang key adalah konsep yang penting untuk memahami keterkaitan antar atribut data dalam tabel dan akan sangat berguna dalam proses normalisasi. Dalam setiap tabel, terdapat 3 macam key:
a) Super key
Super key adalah satu atribut atau gabungan atribut (kolom) pada tabel yang dapat membedakan semua baris secara unik.
b) Candidate key
Candidate key disebut juga dengan minimal super key, yaitu super key yang tidak mengandung super key yang lain. Setiap candidate key pasti merupakan super key, namun tidak semua super key akan menjadi candidate key.
c) Primary key
Primary key adalah salah satu candidate key yang dipilih (dengan berbagai pertimbangan) untuk digunakan dalam DBMS. Tiap tabel hanya memiliki 1 primary key, namun primary key tersebut bisa saja dibentuk dari beberapa atribut (kolom).
Untuk memperjelas pemahaman kita terhadap 3 macam key di atas, perhatikan contohnya pada tabel mata_kuliah di bawah ini:
Beberapa super key dari tabel di atas adalah:
1. (kode_mk)
Dari 6 baris data yang ada pada tabel di atas tak ada satupun yang memiliki kode_mk yang sama.
2. (nama_mk)
Demikian pula dengan nama_mk, masing-masing baris data memiliki nama_mk yang unik. Tidak ada satupun baris data yang memiliki kolom nama_mk dengan nilai yang sama persis.
3. (kode_mk,nama_mk,semester)
Walaupun beberapa baris data memiliki kolom semester dengan nilai yang sama (misalnya baris 1&4, baris 2&3) namun tidak ada satupun baris data yang memiliki kombinasi kode_mk, nama_mk dan semester yang sama persis.
4. (kode_mk,nama_mk, sks)
Kombinasi kode_mk, nama_mk dan sks juga digolongkan sebagai super key dengan alasan yang kurang lebih sama dengan poin 3.
5. (kode_mk,nama_mk, semester, jml_temu)
Kombinasi kode_mk, nama_mk, semester dan jml_temu juga digolongkan sebagai super key dengan alasan yang kurang lebih sama dengan poin 3 dan 4.
Sedangkan yang bukan super key adalah:
1. (sks)
Perhatikan bahwa kolom sks tidak bisa membedakan baris data secara unik, contohnya baris data 2,3, 4 dan 6 sama-sama memiliki kolom sks bernilai 3.
2. (semester)
Kolom semester juga tidak bersifat unik, contohnya baris data 1 dan 4 sama-sama memiliki kolom semester bernilai 2
3. (semester, sks)
Kombinasi semester dan sks juga tidak membedakan tiap baris data secara unik, contohnya baris data ke 2 dan 3 sama-sama memiliki kolom semester bernilai 1 dan sama-sama memiliki kolom sks bernilai 3
Candidate key dari tabel mata_kuliah dipilih dari super key yang sudah ada. Super key yang akan menjadi candidate key adalah super key yang tidak mengandung super key lain di dalamnya.
Perhatikan 5 super key yang sudah kita peroleh dari analisis sebelumnya:
Super key yang hanya teridiri dari satu atribut data pasti akan menjadi candidate key sebab tidak mungkin mengandung super key yang lain. Oleh karena itu super key pada poin 1 dan 2 otomatis menjadi candidate key. Super key pada poin 3 tidak menjadi candidate key sebab dalam kombinasi (kode_mk, nama_mk, semester) terdapat super key yang lain yaitu (kode_mk). Dengan demikian, poin 4 dan 5 juga bukan candidate key.
Dari analisis ini, kita memperoleh 2 buah candidate key yaitu (kode_mk) dan (nama_mk). Salah satu dari beberapa candidate key ini akan dipilih untuk digunakan dalam DBMS sebagai primary key. Ada beberapa pertimbangan untuk memilih primary key, di antaranya adalah jaminan keunikan yang lebih kuat, representasi yang lebih baik dan lain-lain.
3. Functional Dependencies
Functional dependency (FD) atau kebergantungan fungsional adalah constraint atau batasan/ ketentuan antara 2 buah himpunan atribut pada sebuah tabel.
JIka A dan B adalah himpunan atribut dari tabel T, kebergantungan fungsional antara A dan B biasanya dinyatakan dalam notasi notasi A → B. Notasi A → B berarti:
A → B jika memenuhi syarat berikut ini :
Pada sebuah tabel T, jika ada dua baris data atau lebih dengan nilai atribut A yang sama maka baris-baris data tersebut pasti akan memiliki nilai atribut B yang sama Namun hal ini tidak berlaku sebaliknya.
Untuk lebih jelasnya perhatikan tabel berikut ini:
Contoh kebergantungan fungsional yang terdapat pada tabel di atas:
Untuk setiap baris data, jika NIM = 1-01 pasti Nama_mhs = ‘Tukimin’, walaupun belum tentu semua mahasiswa yang bernama Tukimin memiliki NIM = 1-01
NIM → Kd_jur
Untuk setiap baris data, jika NIM = 1-01 pasti Kd_jur = ‘TE’, walaupun tidak semua baris data dengan kd_jur ‘TE’ memiliki kolom NIM bernilai 1-01
NIM → Nama_Jur
Untuk setiap baris data dengan kolom NIM bernilai 1-01 pasti memiliki kolom Nama_Jur = ‘Elektro’, walaupun tidak semua orang di jurusan Elektro memiliki NIM = 1-01. Demikian pula tidak semua baris data pada tabel dengan kolom Nama_Jur = ‘Elektro’ memiliki kolom NIM = 1-01
Penulisan kebergantungan fungsional dari 3 poin di atas dapat diringkas menjadi (NIM) → (nama_mhs, kd_jur, nama_jur)
Dengan demikian, dari tabel tersebut dapat kita simpulkan beberapa kebergantungan fungsional (FD) sebagai berikut:
Ada beberapa jenis kebergantungan fungsional, di antaranya yaitu:
Ketiganya adalah konsep penting dalam normalisasi, namun dalam sub bab ini kita hanya akan membahas mengenai Partial Functional dependency dan Transitive Functional dependency.
1. Partial Funcional Dependency
Partial Functional dependency atau kebergantungan fungsional parsial terjadi bila:
Dengan kata lain jika (B,C) adalah candidate key dan B → A maka A bergantung secara parsial terhadap (B,C) atau (B,C) menentukan A secara parsial.
Untuk lebih jelasnya perhatikan tabel berikut ini:
Pada tabel di atas perhatikan bahwa:
Dari analisis poin 2 dan 3 maka dapat disimpulkan bahwa terjadi kebergantungan fungsional parsial dimana (nama_mhs) bergantung kepada (nim,kode_mk) secara parsial atau dapat juga dikatakan bahwa (nim,kode_mk) menentukan (nama_mhs) secara parsial.
b. Transitive Functional dependency
Transitive Functional dependency atau kebergantungan fungsional transitif terjadi jika:
Jika A → B dan B → C maka A → C. Dengan kata lain A bergantung secara transitif terhadap C melalui B atau A menentukan C secara transitif melalui B.
Untuk lebih jelasnya perhatikan contoh tabel berikut ini:
Dengan demikian dapat disimpulkan bahwa (nama_jur) bergantung secara transitif terhadap (nim) melalui (kd_jur) atau dapat juga dikatakan bahwa (nim) → (nama_jur) secara transitif melalui (kd_jur).
3. Bentuk Normal dan Langkah-Langkah Normalisasi
Bentuk Normal adalah sekumpulan kriteria yang harus dipenuhi oleh sebuah desain tabel untuk mencapai tingkat/level bentuk normal tertentu. Parameter yang biasanya digunakan dalam menentukan kriteria bentuk normal adalah Functional dependency & The Three Keys.
Masing-masing bentuk normal memiliki kriteria dan level tertentu yang tidak mungkin dicapai tanpa memenuhi kriteria bentuk nomal level yang berada di bawahnya. Makin tinggi level bentuk normal yang dicapai maka kualitas desain tabel tersebut dinyatakan makin baik dan semakin kecil peluang terjadinya anomali dan redundansi data.
Normalisasi dilakukan dengan cara menerapkan Bentuk-Bentuk Normal secara bertahap dari level terendah sampai level yang dikehendaki. Walaupun ada beberapa bentuk normal namun jika desain tabel tertentu sudah memenuhi kriteria 3rd NF atau BCNF maka desain tabel itu biasanya dianggap sudah ‘cukup normal’.
a. Bentuk Normal Pertama (1st Normal Form)
Bentuk normal pertama atau First Normal Form (1st NF) adalah bentuk normal yang memiliki level terendah.
Kriteria 1st NF:
Untuk lebih jelasnya perhatikan 2 versi contoh tabel T berikut ini:
Tabel T versi pertama ini memiliki 2 atribut dengan domain yang sama yaitu kolom telp_1 dan telp_2. Hal ini menunjukkan bahwa tabel T versi pertama ini belum memenuhi syarat 1st NF.
Tabel T versi ke dua ini juga belum memenuhi sayarat 1st NF karena kolom telepon bersifat multivalue.
Solusi agar tabel T memenuhi syarat 1st NF adalah dengan melakukan pemecahan tabel atau dekomposisi tabel. Namun perlu diingat, dekomposisi tabel harus dilakukan dengan cermat agar data tetap konsisten (perubahan hanya terjadi pada struktur tabel tapi tidak terjadi perubahan pada data)
Perhatikan bahwa (nim) → (telepon). Dengan demikian, kita dapat memecah tabel T menjadi tabel T-1 dan tabel T-2 berikut ini:
Baik Tabel T1 maupun tabel T2 tidak memiliki atribut bersifat multivalue. Tabel T1 dan T2 juga tidak memiliki lebih dari satu atribut dengan domain yang sama. Dengan demikian dapat disimpulkan bahwa tabel T1 dan T2 telah memenuhi syarat 1st NF dan siap untuk diperiksa apakah memenuhi syarat bentuk normal level berikutnya (2nd NF)
b. Bentuk Normal Ke Dua (2nd Normal Form)
Kriteria 2nd NF:
Desain tabel yang tidak memenuhi syarat 1st NF sudah pasti tidak akan memenuhi syarat 2nd NF
Partial Functional dependency terjadi bila (B,C) adalah candidate key dan B → A
Untuk lebih jelasnya perhatikan tabel T-1hasil tahap sebelumnya:
Perhatikan bahwa:
Berarti Terjadi Partial Functional dependency:
Walaupun tabel T-1 telah memenuhi syarat 1st NF namun karena terjadi partial functional dependency maka tabel T-1 belum memenuhi syarat 2nd NF.
Solusinya adalah dengan melakukan dekomposisi terhadap tabel T-1 dengan tetap menjaga agar datanya tetap konsisten. Hal ini dapat dilakukan dengan melakukan dekomposisi tabel sesuai FD1, FD2 dan FD3 yang telah kita analisis sebelumnya. Adapun hasil dekomposisi dari tabel T-1 adalah 3 tabel berikut ini:
Ketiga tabel hasil dekomposisi tersebut sudah tidak mengalami partial functional dependency. Dengan demikian ketiga tabel tersebut telah memenuhi syarat 2nd NF dan siap untuk diperiksa apakah memenuhi syarat bentuk normal level berikutnya (3rd NF).
Adapun Tabel T-2 (hasil dekomposisi pada tahap 1st NF) juga tidak mengalami partial functional dependency sehingga sudah memenuhi 2nd NF, tidak perlu didekomposisi lagi dan dapat langsung diperiksa apakah memenuhi 3rd NF bersama-sama dengan tabel T-1-1, T-1-2 dan T-1-3.
c. Bentuk Normal Ke Tiga (3rd Normal Form)
Umumnya jika sebuah tabel telah memenuhi syarat bentuk normal ke tiga (3rd NF) maka tabel tersebut sudah dianggap ‘cukup normal’. Bentuk normal ke 3 adalah bentuk normal yang biasanya menjadi syarat minimum bagi sebuah desan tabel walaupun akan lebih baik jika juga memenuhi BCNF.
Kriteria 3rd NF:
Untuk lebih jelasnya perhatikan tabel T-1-1 dari tahap sebelumnya:
Perhatikan bahwa:
Berarti Terjadi Transitive FD:
Walaupun tabel T-1-1 telah memenuhi syarat 2nd NF namun karena terjadi transitive functional dependency maka tabel T1 belum memenuhi syarat 3rd NF. Solusinya adalah dengan melakukan dekomposisi terhadap tabel T-1-1 dengan tetap menjaga agar datanya tetap konsisten sesuai FD1dan FD2. Adapun hasil dekomposisi dari tabel T-1-1 adalah 2 tabel berikut ini:
d. Bentuk Normal Boyce Codd (BC Normal Form)
Boyce Codd Normal Form atau bentuk normal Boyce-Codd adalah bentuk normal yang levelnya di atas 3rd NF. Kriteria BCNF:
Jarang ada kasus dimana sebuah tabel memenuhi 3rd NF tapi tidak memenuhi BCNF. Umumnya sebuah tabel dikategorikan sudah ‘cukup normal’ jika sudah memenuhi kriteria BCNF. Jika tidak memungkinkan untuk memenuhi kriteria BCNF, maka 3rd NF juga sudah dianggap cukup memadai.
e. Bentuk-Bentuk Normal Lainnya
Selain bentuk-bentuk normal yang sudah diperkenalkan pada beberapa sub bab sebelumnya, masih ada beberapa bentuk-bentuk normal lain. Beberapa diantaranya adalah sebagai berikut:
4. Denormalisasi
Denormalisasi adalah proses menggandakan data secara sengaja (sehingga menyebabkan redundansi data) untuk meningkatkan performa database, untuk meningkatkan kecepatan akses data atau memperkecil query cost.
Yang perlu diingat tentang denormalisasi adalah bahwa denormalisasi tidak sama dengan tidak melakukan normalisasi. Denormalisasi dilakukan setelah tabel dalam kondisi ‘cukup normal’ (mencapai level bentuk normal yang dikehendaki).
Salah satu contoh teknik Denormalisasi adalah Materialized View pada DBMS Oracle. Materialized view adalah teknik menggandakan data dengan cara membuat tabel semu berupa view fisik (yang benar-benar dituliskan di disk, bukan sebatas di memory). Materialized view biasanya dibuat dari hasil join beberapa tabel yang sering diakses tapi jarang diupdate.
Materialized view akan menyebabkan redundansi data, namun sebagai imbalannya kecepatan akses data meningkat drastis sebab data dapat langsung diakses melalui materialized view tanpa harus menunggu query menyelesaikan operasi join dari beberapa tabel.
Ada beberapa alasan melakukan denormalisasi:
Adapun konsekuensi denormalisasi adalah sebagai berikut:
Dengan demikian dapat disimpulkan bahwa denormalisasi harus dilakukan dengan bijak sebab walaupun memiliki beberapa keuntungan namun juga memiliki konsekuensi yang patut diperhitungkan.
Sekian artikel tentang Memahami Teknik Normalisasi Lanjut Perancangan Basis Data.
Daftar Pustaka :
Perancangan basis data diperlukan, agar kita bisa memiliki basis data yang kompak dan efisien dalam penggunaan ruang penyimpanan, cepat dalam pengaksesan dan mudah dalam pemanipulasian (tambah, ubah, hapus) data. Dalam merancang basis data, kita dapat melakukannya dengan :
- Menerapkan normalisasi terhadap struktur tabel yang telah diketahui.
- Langsung membuat model Entity–Relationship.
 |
| image source: |
baca juga: Konsep Pemodelan Enhanced Entity Relationship Diagram
1. Definisi Normalisasi
Normalisasi diartikan sebagai suatu teknik yang menstrukturkan/ mendekomposisi/ memecah data dalam cara–cara tertentu untuk mencegah timbulnya permasalahan pengolahan data dalam basis data. Permasalahan yang dimaksud adalah berkaitan dengan penyimpangan–penyimpangan (anomalies) yang terjadi akibat adanya kerangkapan data dalam relasi dan inefisiensi pengolahan.
Proses normalisasi akan menghasilkan relasi yang optimal, yaitu :
- Memiliki struktur record yang mudah untuk dimengerti.
- Memiliki struktur record yang sederhana dalam pemeliharaan.
- Memiliki struktur record yang mudah untuk ditampilkan kembali untuk memenuhi kebutuhan pemakai.
- Minimalisasi kerangkapan data guna meningkatkan kinerja sistem.
Dalam pendekatan normalisasi, perancangan basis data bertitik tolak dari situasi nyata. Ia telah memiliki item–item data yang siap ditempatkan dalam baris dan kolom pada tabel–tabel relasional. Demikian juga dengan sejumlah aturan tentang keterhubungan antara item–item data tersebut. Sementara pendekatan model data ER lebih tepat dilakukan jika yang diketahui baru prinsip sistem secara keseluruhan.
Cukup sering pendekatan ini dilakukan bersama–sama, berganti–ganti. Dari fakta yang telah kita miliki, kita lakukan normalisasi. Untuk kepentingan evaluasi dan dokumentasi, hasil normalisasi itu kita wujudkan dalam sebuah model data. Model data yang sudah jadi tersebut bisa saja dimodifikasi dengan pertimbangan tertentu. Hasil modifikasinya kemudian kita implementasikan dalam bentuk sejumlah struktur tabel dalam sebuah basis data. Struktur ini dapat kita uji kembali dengan menerapkan aturan–aturan normalisasi, hingga akhirnya kita peroleh sebuah struktur basis data yang benar–benar efektif dan efisien. Begitulah kedua pendekatan dapat saling memperkuat satu sama lain.
2. Tujuan Normalisasi
Pada dasarnya normalisasi dilakukan untuk memperbaiki desain tabel yang kurang baik sehingga penyimpanan data menjadi lebih efisien dan bebas anomali data. Untuk memperjelas pemahaman tentang proses normalisasi, perhatikan diagram berikut:
 |
| Gambar 4‑1 Diagram Normalisasi |
Atribut yang sebenarnya identik dengan pemakaian istilah kolom data. Istilah atribut ini lebih umum digunakan dalam perancangan basis data, karena istilah itu lebih impresif dalam menunjukkan fungsinya sebagai pembentuk karakteristik (sifat–sifat) yang melekat pada sebuah table.
a. Atribut Sederhana (Simple Attribute) dan Atribut Komposit (Composite Attribute)
Atribut sederhana adalah atribut atonik yang tidak dapat dipilah lagi. Sementara atribut komposit merupakan atribut yang masih dapat diuraikan lagi menjadi sub–sub atribut yang masing–masing memiliki makna.
Contoh pada tabel mahasiswa, atribut nama_mhs merupakan atribut sederhana. Sedangkan alamat_mhs merupakan atribut komposit, karena dapat diuraikan menjadi beberapa sub atribut seperti alamat, nama_kota dan kode_pos yang masing–masing memiliki makna.
Atribut bernilai tunggal ditujukan pada atribut–atribut yang memiliki paling banyak satu nilai untuk setiap basis data. Pada data mahasiswa, semua atribut (nim, nama_mhs, alamat_mhs dan tgl_lahir) merupakan atribut bernilai tunggal, karena atribut–atribut tersebut hanya dapat berisi 1 (satu) nilai. Jika seorang mahasiswa yang memiliki 2 (dua) tempat tinggal, maka hanya salah satu saja yang boleh diisikan ke dalam atribut alamat_mhs.
Atribut bernilai banyak ditujukan pada atribut–atribut yang dapat kita isi dengan lebih dari 1 (satu) nilai, tetapi jenisnya sama. Kita dapat menambahkan atribut hobi, pada data mahasiswa tersebut. Seorang mahasiswa ada yang mempunyai 1 hobi saja, ada juga yang mempunyai hobi banyak dan bahkan ada mahasiswa yang tidak memiliki hobi. Atribut semacam ini tergolong atribut bernilai banyak.
Ada sejumlah atribut pada sebuah tabel yang kita tetapkan harus berisi data. Jadi nilainya tidak boleh kosong. Atribut semacam ini disebut Mandatory Attribute. Pada tabel mahasiswa, misalnya atribut nim dan nama_mhs dapat kita golongkan sebagai Mandatory Attribute, karena setiap mahasiswa yang datanya ingin disimpan ke tabel tersebut, paling tidak harus diketahui dengan pasti nim dan namanya. Sebaliknya pula atribut–atribut lain suatu tabel yang nilainya boleh dikosongkan (Non Mandatory Attribute). Nilai Null digunakan untuk menyatakan/ mengisi atribut–atribut demikian yang nilainya memang belum siap atau tidak ada.
Atribut turunan adalah atribut yang nilai–nilainya diperbolehkan dari pengolahan atau dapat diturunkan dari atribut atau tabel lain yang berhubungan. Atribut demikian sebetulnya dapat ditiadakan dari sebuah tabel, karena nilai–nilainya bergantung pada nilai yang ada di atribut lainnya.
Penambahan atribut angkatan dan IP (Indeks Prestasi) pada tabel mahasiswa berikut merupakan contoh atribut turunan
Penetapan tipe data pada setiap atribut (kolom) untuk keperluan penentuan struktur setiap tabel. Penetapan tipe data ini akan berimplikasi pada adanya batas–batas nilai yang mungkin disimpan/diisikan kesetiap atribut tersebut. Jika kita menetapkan bahwa tipe data untuk sebuah atribut adalah integer, maka kita hanya mungkin untuk menyimpan data angka yang bulat diantara –32.768 hingga 32.768. Kita tidak mungkin untuk memasukkan data diluar batas nilai tersebut, data pecahan apalagi data berupa string/text.
Domain memiliki banyak kesamaan pengertian dengan fungsi tipe data tersebut. Akan tetapi, tipe data merujuk pada kemampuan penyimpanan data yang mungkin bagi suatu atribut secara fisik, tanpa melihat layak tidaknya data tersebut bila dilihat dari kenyataannya pemakaiannya. Sementara domain nilai lebih ditetapkan pada batas–batas nilai yang diperbolehkan bagi suatu atribut, dilihat dari kenyataanya yang ada.
Contoh : pada tabel kuliah, ditetapkan tipe data untuk atribut sks adalah integer. Dengan begitu secara fisik kita dapat menyimpan nilai –1, 0 atau 100 untuk atribut sks. Tetapi kita mengetahui dengan pasti, bahwa nilai–nilai tersebut tidak pantas (invalid) untuk menjadi data pada atribut sks. Lalu nilai–nilai yang boleh (valid) untuk atribut sks adalah 1, 2, 3, 4 dan 6, maka dapat dikatakan, domain nilai untuk atribut sks adalah 1, 2, 3, 4 dan 6.
Intinya, normalisasi dilakukan terhadap desain tabel yang sudah ada dengan tujuan untuk meminimalkan redundansi (pengulangan) data dan menjamin integritas data dengan cara menghidari 3 Anomali Data: Update, Insertion dan Deletion Anomaly.
a. Update Anomaly
 |
| Tabel 4‑1 Contoh Update Anomaly |
Jika hanya salah satu baris saja yang di-update, maka data menjadi tidak konsisten (ada mata kuliah English dengan 2 sks dan ada mata kuliah English dengan 3 sks) . Kondisi seperti inilah yang disebut dengan update anomaly.
b. Insertion Anomaly
 |
| Tabel 4‑2 Contoh Insert Anomaly |
Data mahasiswa tersebut tidak dapat dimasukkan ke dalam tabel sebab dia belum mengambil kuliah apapun (misalnya karena belum melakukan registrasi). Kondisi inilah yang disebut dengan insertion anomaly.
c. Deletion Anomaly
 |
| Tabel 4‑3 Contoh Delete Anomaly |
Selain 3 anomali di atas, ada beberapa konsep yang mendasari normalisasi. Adapun konsep-konsep penting yang mendasari normalisasi adalah konsep mengenai super key, candidate key, primary key, functional dependency dan tentu saja bentuk-bentuk normal yang menjadi acuan kita dalam melakukan normalisasi terhadap desain sebuah tabel. Pemahaman terhadap konsep-konsep ini sangat penting dan akan dibahas di beberapa sub bab berikutnya.
2. The Three Keys
Konsep tentang key adalah konsep yang penting untuk memahami keterkaitan antar atribut data dalam tabel dan akan sangat berguna dalam proses normalisasi. Dalam setiap tabel, terdapat 3 macam key:
a) Super key
Super key adalah satu atribut atau gabungan atribut (kolom) pada tabel yang dapat membedakan semua baris secara unik.
b) Candidate key
Candidate key disebut juga dengan minimal super key, yaitu super key yang tidak mengandung super key yang lain. Setiap candidate key pasti merupakan super key, namun tidak semua super key akan menjadi candidate key.
c) Primary key
Primary key adalah salah satu candidate key yang dipilih (dengan berbagai pertimbangan) untuk digunakan dalam DBMS. Tiap tabel hanya memiliki 1 primary key, namun primary key tersebut bisa saja dibentuk dari beberapa atribut (kolom).
Untuk memperjelas pemahaman kita terhadap 3 macam key di atas, perhatikan contohnya pada tabel mata_kuliah di bawah ini:
 |
| Tabel 4‑4 Tabel Mata Kuliah |
1. (kode_mk)
Dari 6 baris data yang ada pada tabel di atas tak ada satupun yang memiliki kode_mk yang sama.
2. (nama_mk)
Demikian pula dengan nama_mk, masing-masing baris data memiliki nama_mk yang unik. Tidak ada satupun baris data yang memiliki kolom nama_mk dengan nilai yang sama persis.
3. (kode_mk,nama_mk,semester)
Walaupun beberapa baris data memiliki kolom semester dengan nilai yang sama (misalnya baris 1&4, baris 2&3) namun tidak ada satupun baris data yang memiliki kombinasi kode_mk, nama_mk dan semester yang sama persis.
4. (kode_mk,nama_mk, sks)
Kombinasi kode_mk, nama_mk dan sks juga digolongkan sebagai super key dengan alasan yang kurang lebih sama dengan poin 3.
5. (kode_mk,nama_mk, semester, jml_temu)
Kombinasi kode_mk, nama_mk, semester dan jml_temu juga digolongkan sebagai super key dengan alasan yang kurang lebih sama dengan poin 3 dan 4.
Sedangkan yang bukan super key adalah:
1. (sks)
Perhatikan bahwa kolom sks tidak bisa membedakan baris data secara unik, contohnya baris data 2,3, 4 dan 6 sama-sama memiliki kolom sks bernilai 3.
2. (semester)
Kolom semester juga tidak bersifat unik, contohnya baris data 1 dan 4 sama-sama memiliki kolom semester bernilai 2
3. (semester, sks)
Kombinasi semester dan sks juga tidak membedakan tiap baris data secara unik, contohnya baris data ke 2 dan 3 sama-sama memiliki kolom semester bernilai 1 dan sama-sama memiliki kolom sks bernilai 3
Candidate key dari tabel mata_kuliah dipilih dari super key yang sudah ada. Super key yang akan menjadi candidate key adalah super key yang tidak mengandung super key lain di dalamnya.
Perhatikan 5 super key yang sudah kita peroleh dari analisis sebelumnya:
- (kode_mk)
- (nama_mk)
- (kode_mk,nama_mk,semester)
- (kode_mk,nama_mk, sks)
- (kode_mk,nama_mk, semester, jml_temu)
Super key yang hanya teridiri dari satu atribut data pasti akan menjadi candidate key sebab tidak mungkin mengandung super key yang lain. Oleh karena itu super key pada poin 1 dan 2 otomatis menjadi candidate key. Super key pada poin 3 tidak menjadi candidate key sebab dalam kombinasi (kode_mk, nama_mk, semester) terdapat super key yang lain yaitu (kode_mk). Dengan demikian, poin 4 dan 5 juga bukan candidate key.
Dari analisis ini, kita memperoleh 2 buah candidate key yaitu (kode_mk) dan (nama_mk). Salah satu dari beberapa candidate key ini akan dipilih untuk digunakan dalam DBMS sebagai primary key. Ada beberapa pertimbangan untuk memilih primary key, di antaranya adalah jaminan keunikan yang lebih kuat, representasi yang lebih baik dan lain-lain.
3. Functional Dependencies
Functional dependency (FD) atau kebergantungan fungsional adalah constraint atau batasan/ ketentuan antara 2 buah himpunan atribut pada sebuah tabel.
JIka A dan B adalah himpunan atribut dari tabel T, kebergantungan fungsional antara A dan B biasanya dinyatakan dalam notasi notasi A → B. Notasi A → B berarti:
- A menentukan B
- B secara fungsional bergantung kepada A.
A → B jika memenuhi syarat berikut ini :
Pada sebuah tabel T, jika ada dua baris data atau lebih dengan nilai atribut A yang sama maka baris-baris data tersebut pasti akan memiliki nilai atribut B yang sama Namun hal ini tidak berlaku sebaliknya.
Untuk lebih jelasnya perhatikan tabel berikut ini:
 |
| Tabel 4‑5 Contoh Tabel |
- NIM → Nama_mhs
Untuk setiap baris data, jika NIM = 1-01 pasti Nama_mhs = ‘Tukimin’, walaupun belum tentu semua mahasiswa yang bernama Tukimin memiliki NIM = 1-01
NIM → Kd_jur
Untuk setiap baris data, jika NIM = 1-01 pasti Kd_jur = ‘TE’, walaupun tidak semua baris data dengan kd_jur ‘TE’ memiliki kolom NIM bernilai 1-01
NIM → Nama_Jur
Untuk setiap baris data dengan kolom NIM bernilai 1-01 pasti memiliki kolom Nama_Jur = ‘Elektro’, walaupun tidak semua orang di jurusan Elektro memiliki NIM = 1-01. Demikian pula tidak semua baris data pada tabel dengan kolom Nama_Jur = ‘Elektro’ memiliki kolom NIM = 1-01
Penulisan kebergantungan fungsional dari 3 poin di atas dapat diringkas menjadi (NIM) → (nama_mhs, kd_jur, nama_jur)
Dengan demikian, dari tabel tersebut dapat kita simpulkan beberapa kebergantungan fungsional (FD) sebagai berikut:
- FD1: (nim) → (nama_mhs, kd_jur, nama_jur)
- FD2: (kd_jur) → (nama_jur)
- FD3: (kode_mk) → (nama_mk, sks)
- FD4: (nim,kode_mk) → (nilai)
Ada beberapa jenis kebergantungan fungsional, di antaranya yaitu:
- Partial Functional dependency
- Transitive Functional dependency
- Multivalued Functional dependency
Ketiganya adalah konsep penting dalam normalisasi, namun dalam sub bab ini kita hanya akan membahas mengenai Partial Functional dependency dan Transitive Functional dependency.
1. Partial Funcional Dependency
Partial Functional dependency atau kebergantungan fungsional parsial terjadi bila:
- B → A
- B adalah bagian dari candidate key
Dengan kata lain jika (B,C) adalah candidate key dan B → A maka A bergantung secara parsial terhadap (B,C) atau (B,C) menentukan A secara parsial.
Untuk lebih jelasnya perhatikan tabel berikut ini:
 |
| Tabel 4‑6 Tabel Nilai |
- Super key : (nim,kode_mk), (nim,nama_mhs,kode_mk) dan (nim,nama_mhs,kode_mk,nilai)
- Dari super key yang sudah diperoleh pada poin 1, maka dipilih super key yang akan menjadi candidate key yaitu (nim,kode_mk)
- FD: (nim) → (nama_mhs)
Dari analisis poin 2 dan 3 maka dapat disimpulkan bahwa terjadi kebergantungan fungsional parsial dimana (nama_mhs) bergantung kepada (nim,kode_mk) secara parsial atau dapat juga dikatakan bahwa (nim,kode_mk) menentukan (nama_mhs) secara parsial.
b. Transitive Functional dependency
Transitive Functional dependency atau kebergantungan fungsional transitif terjadi jika:
- A → B
- B → C
Jika A → B dan B → C maka A → C. Dengan kata lain A bergantung secara transitif terhadap C melalui B atau A menentukan C secara transitif melalui B.
Untuk lebih jelasnya perhatikan contoh tabel berikut ini:
 |
| Tabel 4‑7 Tabel Mahasiswa |
- FD1: (nim) → (nama_mhs, kd_jur, nama_jur)
- FD2: (kd_jur) → (nama_jur)
Dengan demikian dapat disimpulkan bahwa (nama_jur) bergantung secara transitif terhadap (nim) melalui (kd_jur) atau dapat juga dikatakan bahwa (nim) → (nama_jur) secara transitif melalui (kd_jur).
3. Bentuk Normal dan Langkah-Langkah Normalisasi
Bentuk Normal adalah sekumpulan kriteria yang harus dipenuhi oleh sebuah desain tabel untuk mencapai tingkat/level bentuk normal tertentu. Parameter yang biasanya digunakan dalam menentukan kriteria bentuk normal adalah Functional dependency & The Three Keys.
Masing-masing bentuk normal memiliki kriteria dan level tertentu yang tidak mungkin dicapai tanpa memenuhi kriteria bentuk nomal level yang berada di bawahnya. Makin tinggi level bentuk normal yang dicapai maka kualitas desain tabel tersebut dinyatakan makin baik dan semakin kecil peluang terjadinya anomali dan redundansi data.
Normalisasi dilakukan dengan cara menerapkan Bentuk-Bentuk Normal secara bertahap dari level terendah sampai level yang dikehendaki. Walaupun ada beberapa bentuk normal namun jika desain tabel tertentu sudah memenuhi kriteria 3rd NF atau BCNF maka desain tabel itu biasanya dianggap sudah ‘cukup normal’.
a. Bentuk Normal Pertama (1st Normal Form)
Bentuk normal pertama atau First Normal Form (1st NF) adalah bentuk normal yang memiliki level terendah.
Kriteria 1st NF:
- Tidak ada atribut (kolom) pada tabel yang bersifat multi-value
Sebuah atribut disebut bersifat multivalue jika dalam sebuah baris data pada kolom tersbut terdapat lebih dari satu nilai. Misalnya kolom telepon yang berisi ‘0813xx, 022xxx’ dan seterusnya. - Tidak memiliki lebih dari satu atribut dengn domain yang sama
Sebuah tabel dikatakan memiliki lebih dari satu atribut dengan domain yang sama jika pada tabel tersebut terdapat lebih dari satu kolom yang digunakan untuk menyimpan data yang jenisnya sama. Misalnya kolom telepon1, telepon2, telepon3 dan seterusnya.
Untuk lebih jelasnya perhatikan 2 versi contoh tabel T berikut ini:
 |
| Tabel 4‑8 Versi pertama |
 |
| Tabel 4‑9 Versi ke dua |
Solusi agar tabel T memenuhi syarat 1st NF adalah dengan melakukan pemecahan tabel atau dekomposisi tabel. Namun perlu diingat, dekomposisi tabel harus dilakukan dengan cermat agar data tetap konsisten (perubahan hanya terjadi pada struktur tabel tapi tidak terjadi perubahan pada data)
Perhatikan bahwa (nim) → (telepon). Dengan demikian, kita dapat memecah tabel T menjadi tabel T-1 dan tabel T-2 berikut ini:
 |
| Tabel 4‑10 Contoh Tabel T-1 |
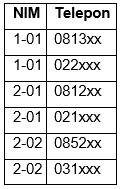 |
| Tabel 4‑11 Contoh Tabel T-2 |
b. Bentuk Normal Ke Dua (2nd Normal Form)
Kriteria 2nd NF:
- Memenuhi 1st NF
Desain tabel yang tidak memenuhi syarat 1st NF sudah pasti tidak akan memenuhi syarat 2nd NF
- Tidak ada Partial Functional dependency
Partial Functional dependency terjadi bila (B,C) adalah candidate key dan B → A
Untuk lebih jelasnya perhatikan tabel T-1hasil tahap sebelumnya:
 |
| Tabel 4‑12 Contoh T-1hasil |
- (nim, kode_mk) adalah candidate key
- FD1: (nim) → (nama_mhs, kd_jur, nama_jur)
- FD2: (kode_mk) → (nama_mk, sks)
- FD3: (nim,kode_mk) → nilai
Berarti Terjadi Partial Functional dependency:
- FD 1: (nim,kode_mk) → (nama_mhs,kd_jur,nama_jur) secara parsial
- FD 2: (nim,kode_mk) → (nama_mk,sks) secara parsial
Walaupun tabel T-1 telah memenuhi syarat 1st NF namun karena terjadi partial functional dependency maka tabel T-1 belum memenuhi syarat 2nd NF.
Solusinya adalah dengan melakukan dekomposisi terhadap tabel T-1 dengan tetap menjaga agar datanya tetap konsisten. Hal ini dapat dilakukan dengan melakukan dekomposisi tabel sesuai FD1, FD2 dan FD3 yang telah kita analisis sebelumnya. Adapun hasil dekomposisi dari tabel T-1 adalah 3 tabel berikut ini:
 |
| Tabel 4‑13 Contoh Tabel T-1-1 |
 |
| Tabel 4‑14 Contoh Tabel T-1-2 |
 |
| Tabel 4‑15 Contoh Tabel T-1-3 |
Adapun Tabel T-2 (hasil dekomposisi pada tahap 1st NF) juga tidak mengalami partial functional dependency sehingga sudah memenuhi 2nd NF, tidak perlu didekomposisi lagi dan dapat langsung diperiksa apakah memenuhi 3rd NF bersama-sama dengan tabel T-1-1, T-1-2 dan T-1-3.
c. Bentuk Normal Ke Tiga (3rd Normal Form)
Umumnya jika sebuah tabel telah memenuhi syarat bentuk normal ke tiga (3rd NF) maka tabel tersebut sudah dianggap ‘cukup normal’. Bentuk normal ke 3 adalah bentuk normal yang biasanya menjadi syarat minimum bagi sebuah desan tabel walaupun akan lebih baik jika juga memenuhi BCNF.
Kriteria 3rd NF:
- Memenuhi 2nd NF
Desain tabel yang tidak memenuhi syarat 2nd NF sudah pasti tidak akan memenuhi syarat 3rd NF - Tidak ada Transitive Functional dependency
Transitive functional dependency terjadi bila AàB dan BàC
Untuk lebih jelasnya perhatikan tabel T-1-1 dari tahap sebelumnya:
 |
| Tabel 4‑16 Contoh tabel T-1-1 |
- FD1: (nim) → (nama_mhs, kd_jur, nama_jur)
- FD2: (kd_jur) → (nama_jur)
Berarti Terjadi Transitive FD:
- (nim) → (nama_jur) secara transitif melalui (kd_jur)
Walaupun tabel T-1-1 telah memenuhi syarat 2nd NF namun karena terjadi transitive functional dependency maka tabel T1 belum memenuhi syarat 3rd NF. Solusinya adalah dengan melakukan dekomposisi terhadap tabel T-1-1 dengan tetap menjaga agar datanya tetap konsisten sesuai FD1dan FD2. Adapun hasil dekomposisi dari tabel T-1-1 adalah 2 tabel berikut ini:
 |
| Tabel 4‑17 Contoh Tabel T-1-1-1 |
 |
| Tabel 4‑18 Contoh Tabel T-1-1-2 |
Boyce Codd Normal Form atau bentuk normal Boyce-Codd adalah bentuk normal yang levelnya di atas 3rd NF. Kriteria BCNF:
- Memenuhi 3rd NF
Desain tabel yang tidak memenuhi syarat 3rd NF sudah pasti tidak akan memenuhi syarat BCNF - Untuk semua FD yang terdapat di tabel, ruas kiri dari FD tersebut adalah super key
Jika ada satu saja FD pada tabel dimana ruas kirinya bukan super key maka desain tabel tersebut belum memenuhi syarat BCNF. Solusinya adalah dengan melakukan dekomposisi tabel dan tetap mempertahankan konsistensi data seperti beberapa contoh pada sub bab sebelumnya
e. Bentuk-Bentuk Normal Lainnya
Selain bentuk-bentuk normal yang sudah diperkenalkan pada beberapa sub bab sebelumnya, masih ada beberapa bentuk-bentuk normal lain. Beberapa diantaranya adalah sebagai berikut:
- Bentuk Normal ke-4 (4th NF)
diperkenalkan oleh Ronald Fagin pada tahun 1977 - Bentuk Normal ke-5 (5th NF)
diperkenalkan oleh Ronald Fagin pada tahun 1979 - Domain/Key Normal Form (DKNF)
diperkenalkan oleh Ronald Fagin pada tahun 1981 - Bentuk Normal ke-6 (6th NF)
diperkenalkan oleh Date, Darwen dan Lorentzos pada tahun 2002
4. Denormalisasi
Denormalisasi adalah proses menggandakan data secara sengaja (sehingga menyebabkan redundansi data) untuk meningkatkan performa database, untuk meningkatkan kecepatan akses data atau memperkecil query cost.
Yang perlu diingat tentang denormalisasi adalah bahwa denormalisasi tidak sama dengan tidak melakukan normalisasi. Denormalisasi dilakukan setelah tabel dalam kondisi ‘cukup normal’ (mencapai level bentuk normal yang dikehendaki).
Salah satu contoh teknik Denormalisasi adalah Materialized View pada DBMS Oracle. Materialized view adalah teknik menggandakan data dengan cara membuat tabel semu berupa view fisik (yang benar-benar dituliskan di disk, bukan sebatas di memory). Materialized view biasanya dibuat dari hasil join beberapa tabel yang sering diakses tapi jarang diupdate.
Materialized view akan menyebabkan redundansi data, namun sebagai imbalannya kecepatan akses data meningkat drastis sebab data dapat langsung diakses melalui materialized view tanpa harus menunggu query menyelesaikan operasi join dari beberapa tabel.
Ada beberapa alasan melakukan denormalisasi:
- Mempercepat proses query dengan cara meminimalkan cost yang disebabkan oleh operasi join antar tabel
- Untuk keperluan Online Analytical Process (OLAP)
- Dan lain-lain
Adapun konsekuensi denormalisasi adalah sebagai berikut:
- Perlu ruang ekstra untuk penyimpanan data
- Memperlambat pada saat proses insert, update dan delete sebab proses-proses tersebut harus dilakukan terhadap data yang redundant (ganda)
Dengan demikian dapat disimpulkan bahwa denormalisasi harus dilakukan dengan bijak sebab walaupun memiliki beberapa keuntungan namun juga memiliki konsekuensi yang patut diperhitungkan.
Sekian artikel tentang Memahami Teknik Normalisasi Lanjut Perancangan Basis Data.
Daftar Pustaka :
- Connoly, Thomas; Begg, Carolyn; Strachan, Anne; Database Systems : A Practical Approach to Design, Implementation and Management, 3rd edition, Addison Wesley, 2001.
- C.J. Date, An Introduction to Database System, 6th ed., Addison-wesley Publishing Company, 1995
- Date, C.J.; An Introduction to Database System, Addison Wesley Publishing Company, Vol. 7, New York, 2000.
- Elmasre, Ramez; Navathe, Shamkant B.; Fundamentals of Database Systems, The Benjamin/Cummings Publishing Company, Inc., California, 2001.
- Fathansyah, Basis Data, Penerbit Informatika, Bandung, 2002
- Flerning, Candace C, Handbook of Relational Database Design, Addison-Wesley Publishing Company.
- Jeffrey D. Ullman, Principles of Database Systems, 2nd ed, Computer Science Press, 1982.
- Korth, H.; Database System Concept, Mc Graw Hill, 4th edition, New York, 2002

{kind=link}
Posting Komentar untuk "Memahami Teknik Normalisasi Lanjut Perancangan Basis Data"
Tata tertib berkomentar
1. Komentar harus relevan dengan konten yang dibaca
2. Gunakan bahasa yang sopan
3. Tidak mengandung unsur SARA or Bullying.
4. Dilarang SPAM.
5. Dilarang menyisipkan link aktif pada isi komentar.
Berlakulah dengan bijak dalam menggunakan sarana publik ini. Baca dan pahami isinya terlebih dahulu, barulah Berkomentar. Terimakasih.